無料でクラウドストレージから最新のGoShiken ACD301 PDFダンプをダウンロードする:https://drive.google.com/open?id=1WXbA_uGgK6eQn3hL9mzAWgE2_Cjv3PHi
我々社のAppian ACD301問題集を購入するかどうかと疑問があると、弊社GoShikenのACD301問題集のサンプルをしてみるのもいいことです。試用した後、我々のACD301問題集はあなたを試験に順調に合格させると信じられます。なぜと言うのは、我々社の専門家は改革に応じて問題の更新と改善を続けていくのは出発点から勝つからです。
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
| トピック 4 |
|
| トピック 5 |
|
信頼できるACD301の質問と回答は、その分野で豊富な経験を持つ専門家によって開発されました。 ACD301準備ガイドの絶え間ない更新により、試験問題の高い精度が維持されるため、ACD301試験をすばやく使用できます。試験中は、ACD301の質問と回答で練習した質問に精通しています。また、ACD301試験問題は非常に正確で有効であるため、合格率は99%〜100%です。それが、ほとんどのお客様が常にACD301試験に簡単に合格する理由です。
質問 # 27
You need to export data using an out-of-the-box Appian smart service. Which two formats are available (or data generation?
正解:A、D
解説:
The two formats that are available for data generation using an out-of-the-box Appian smart service are:
* A. CSV. This is a comma-separated values format that can be used to export data in a tabular form, such as records, reports, or grids. CSV files can be easily opened and manipulated by spreadsheet applications such as Excel or Google Sheets.
* C. Excel. This is a format that can be used to export data in a spreadsheet form, with multiple worksheets, formatting, formulas, charts, and other features. Excel files can be opened by Excel or other compatible applications.
The other options are incorrect for the following reasons:
* B. XML. This is a format that can be used to export data in a hierarchical form, using tags and attributes to define the structure and content of the data. XML files can be opened by text editors or XML parsers, but they are not supported by the out-of-the-box Appian smart service for data generation.
* D. JSON. This is a format that can be used to export data in a structured form, using objects and arrays to represent the data. JSON files can be opened by text editors or JSON parsers, but they are not supported by the out-of-the-box Appian smart service for data generation. Verified References: Appian Documentation, section "Write to Data Store Entity" and "Write to Multiple Data Store Entities".
質問 # 28
You are required to create an integration from your Appian Cloud instance to an application hosted within a customer's self-managed environment.
The customer's IT team has provided you with a REST API endpoint to test with: https://internal.network/api/api/ping.
Which recommendation should you make to progress this integration?
正解:A
解説:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating an Appian Cloud instance with a customer's self-managed (on-premises) environment requires addressing network connectivity, security, and Appian's cloud architecture constraints. The provided endpoint (https://internal.network/api/api/ping) is a REST API on an internal network, inaccessible directly from Appian Cloud due to firewall restrictions and lack of public exposure. Let's evaluate each option:
A . Expose the API as a SOAP-based web service:
Converting the REST API to SOAP isn't a practical recommendation. The customer has provided a REST endpoint, and Appian fully supports REST integrations via Connected Systems and Integration objects. Changing the API to SOAP adds unnecessary complexity, development effort, and risks for the customer, with no benefit to Appian's integration capabilities. Appian's documentation emphasizes using the API's native format (REST here), making this irrelevant.
B . Deploy the API/service into Appian Cloud:
Deploying the customer's API into Appian Cloud is infeasible. Appian Cloud is a managed PaaS environment, not designed to host customer applications or APIs. The API resides in the customer's self-managed environment, and moving it would require significant architectural changes, violating security and operational boundaries. Appian's integration strategy focuses on connecting to external systems, not hosting them, ruling this out.
C . Add Appian Cloud's IP address ranges to the customer network's allowed IP listing:
This approach involves whitelisting Appian Cloud's IP ranges (available in Appian documentation) in the customer's firewall to allow direct HTTP/HTTPS requests. However, Appian Cloud's IPs are dynamic and shared across tenants, making this unreliable for long-term integrations-changes in IP ranges could break connectivity. Appian's best practices discourage relying on IP whitelisting for cloud-to-on-premises integrations due to this limitation, favoring secure tunnels instead.
D . Set up a VPN tunnel:
This is the correct recommendation. A Virtual Private Network (VPN) tunnel establishes a secure, encrypted connection between Appian Cloud and the customer's self-managed network, allowing Appian to access the internal REST API (https://internal.network/api/api/ping). Appian supports VPNs for cloud-to-on-premises integrations, and this approach ensures reliability, security, and compliance with network policies. The customer's IT team can configure the VPN, and Appian's documentation recommends this for such scenarios, especially when dealing with internal endpoints.
Conclusion: Setting up a VPN tunnel (D) is the best recommendation. It enables secure, reliable connectivity from Appian Cloud to the customer's internal API, aligning with Appian's integration best practices for cloud-to-on-premises scenarios.
Reference:
Appian Documentation: "Integrating Appian Cloud with On-Premises Systems" (VPN and Network Configuration).
Appian Lead Developer Certification: Integration Module (Cloud-to-On-Premises Connectivity).
Appian Best Practices: "Securing Integrations with Legacy Systems" (VPN Recommendations).
質問 # 29
As part of your implementation workflow, users need to retrieve data stored in a third-party Oracle database on an interface. You need to design a way to query this information.
How should you set up this connection and query the data?
正解:C
解説:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a solution to query data from a third-party Oracle database for display on an interface requires secure, efficient, and maintainable integration. The scenario focuses on real-time retrieval for users, so the design must leverage Appian's data connectivity features. Let's evaluate each option:
A . Configure a Query Database node within the process model. Then, type in the connection information, as well as a SQL query to execute and return the data in process variables:
The Query Database node (part of the Smart Services) allows direct SQL execution against a database, but it requires manual connection details (e.g., JDBC URL, credentials), which isn't scalable or secure for Production. Appian's documentation discourages using Query Database for ongoing integrations due to maintenance overhead, security risks (e.g., hardcoding credentials), and lack of governance. This is better for one-off tasks, not real-time interface queries, making it unsuitable.
B . Configure a timed utility process that queries data from the third-party database daily, and stores it in the Appian business database. Then use a!queryEntity using the Appian data source to retrieve the data:
This approach syncs data daily into Appian's business database (e.g., via a timer event and Query Database node), then queries it with a!queryEntity. While it works for stale data, it introduces latency (up to 24 hours) for users, which doesn't meet real-time needs on an interface. Appian's best practices recommend direct data source connections for up-to-date data, not periodic caching, unless latency is acceptable-making this inefficient here.
C . Configure an expression-backed record type, calling an API to retrieve the data from the third-party database. Then, use a!queryRecordType to retrieve the data:
Expression-backed record types use expressions (e.g., a!httpQuery()) to fetch data, but they're designed for external APIs, not direct database queries. The scenario specifies an Oracle database, not an API, so this requires building a custom REST service on the Oracle side, adding complexity and latency. Appian's documentation favors Data Sources for database queries over API calls when direct access is available, making this less optimal and over-engineered.
D . In the Administration Console, configure the third-party database as a "New Data Source." Then, use a!queryEntity to retrieve the data:
This is the best choice. In the Appian Administration Console, you can configure a JDBC Data Source for the Oracle database, providing connection details (e.g., URL, driver, credentials). This creates a secure, managed connection for querying via a!queryEntity, which is Appian's standard function for Data Store Entities. Users can then retrieve data on interfaces using expression-backed records or queries, ensuring real-time access with minimal latency. Appian's documentation recommends Data Sources for database integrations, offering scalability, security, and governance-perfect for this requirement.
Conclusion: Configuring the third-party database as a New Data Source and using a!queryEntity (D) is the recommended approach. It provides direct, real-time access to Oracle data for interface display, leveraging Appian's native data connectivity features and aligning with Lead Developer best practices for third-party database integration.
Reference:
Appian Documentation: "Configuring Data Sources" (JDBC Connections and a!queryEntity).
Appian Lead Developer Certification: Data Integration Module (Database Query Design).
Appian Best Practices: "Retrieving External Data in Interfaces" (Data Source vs. API Approaches).
質問 # 30
You are selling up a new cloud environment. The customer already has a system of record for Its employees and doesn't want to re-create them in Appian. so you are going to Implement LDAP authentication.
What are the next steps to configure LDAP authentication?
To answer, move the appropriate steps from the Option list to the Answer List area, and arrange them in the correct order. You may or may not use all the steps.
正解:
解説: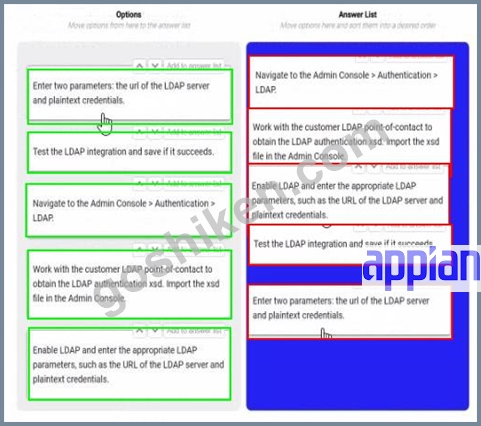
質問 # 31
You are designing a process that is anticipated to be executed multiple times a day. This process retrieves data from an external system and then calls various utility processes as needed. The main process will not use the results of the utility processes, and there are no user forms anywhere.
Which design choice should be used to start the utility processes and minimize the load on the execution engines?
正解:C
解説:
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a process that executes frequently (multiple times a day) and calls utility processes without using their results requires optimizing performance and minimizing load on Appian's execution engines. The absence of user forms indicates a backend process, so user experience isn't a concern-only engine efficiency matters. Let's evaluate each option:
A . Use the Start Process Smart Service to start the utility processes:
The Start Process Smart Service launches a new process instance independently, creating a separate process in the Work Queue. While functional, it increases engine load because each utility process runs as a distinct instance, consuming engine resources and potentially clogging the Java Work Queue, especially with frequent executions. Appian's performance guidelines discourage unnecessary separate process instances for utility tasks, favoring integrated subprocesses, making this less optimal.
B . Start the utility processes via a subprocess synchronously:
Synchronous subprocesses (e.g., a!startProcess with isAsync: false) execute within the main process flow, blocking until completion. For utility processes not used by the main process, this creates unnecessary delays, increasing execution time and engine load. With frequent daily executions, synchronous subprocesses could strain engines, especially if utility processes are slow or numerous. Appian's documentation recommends asynchronous execution for non-dependent, non-blocking tasks, ruling this out.
C . Use Process Messaging to start the utility process:
Process Messaging (e.g., sendMessage() in Appian) is used for inter-process communication, not for starting processes. It's designed to pass data between running processes, not initiate new ones. Attempting to use it for starting utility processes would require additional setup (e.g., a listening process) and isn't a standard or efficient method. Appian's messaging features are for coordination, not process initiation, making this inappropriate.
D . Start the utility processes via a subprocess asynchronously:
This is the best choice. Asynchronous subprocesses (e.g., a!startProcess with isAsync: true) execute independently of the main process, offloading work to the engine without blocking or delaying the parent process. Since the main process doesn't use the utility process results and there are no user forms, asynchronous execution minimizes engine load by distributing tasks across time, reducing Work Queue pressure during frequent executions. Appian's performance best practices recommend asynchronous subprocesses for non-dependent, utility tasks to optimize engine utilization, making this ideal for minimizing load.
Conclusion: Starting the utility processes via a subprocess asynchronously (D) minimizes engine load by allowing independent execution without blocking the main process, aligning with Appian's performance optimization strategies for frequent, backend processes.
Reference:
Appian Documentation: "Process Model Performance" (Synchronous vs. Asynchronous Subprocesses).
Appian Lead Developer Certification: Process Design Module (Optimizing Engine Load).
Appian Best Practices: "Designing Efficient Utility Processes" (Asynchronous Execution).
質問 # 32
......
ブラウジング中の支払いのセキュリティが心配ですか? ACD301テストトレントは、購入プロセスのセキュリティ、製品のダウンロード、インストールを安全でウイルスのないものにすることができます。この点について疑問がある場合は、専門の担当者がインストールと使用をリモートでガイドします。 ACD301テスト回答の購入プロセスは非常に簡単で、単純な人にとっては大きな恩恵です。ACD301学習教材の合格率は彼らのものよりもはるかに高いことを保証できます。そしてこれが最も重要です。以前のデータによると、ACD301トレーニング質問を使用する人の98%〜99%が試験に合格しました。あなたが私たちに信頼を与えてくれるなら、私たちはあなたに成功を与えます。
ACD301資格準備: https://www.goshiken.com/Appian/ACD301-mondaishu.html
2025年GoShikenの最新ACD301 PDFダンプおよびACD301試験エンジンの無料共有:https://drive.google.com/open?id=1WXbA_uGgK6eQn3hL9mzAWgE2_Cjv3PHi
