DOWNLOAD the newest VCE4Dumps Databricks-Generative-AI-Engineer-Associate PDF dumps from Cloud Storage for free: https://drive.google.com/open?id=1t5O376pJ7IPTBazX4_CDV6XhnqxwTbhG
VCE4Dumps also offers Databricks Databricks-Generative-AI-Engineer-Associate desktop practice exam software which is accessible without any internet connection after the verification of the required license. This software is very beneficial for all those applicants who want to prepare in a scenario which is similar to the Databricks Certified Generative AI Engineer Associate real examination.
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
>> Databricks-Generative-AI-Engineer-Associate New Question <<
For most users, access to the relevant qualifying examinations may be the first, so many of the course content related to qualifying examinations are complex and arcane. According to these ignorant beginners, the Databricks-Generative-AI-Engineer-Associate exam questions set up a series of basic course, by easy to read, with corresponding examples to explain at the same time, the Databricks-Generative-AI-Engineer-Associate study question let the user to be able to find in real life and corresponds to the actual use of Databricks-Generative-AI-Engineer-Associate learned knowledge. And it will only takes 20 to 30 hours for them to pass the Databricks-Generative-AI-Engineer-Associate exam.
NEW QUESTION # 21
A Generative Al Engineer is developing a RAG application and would like to experiment with different embedding models to improve the application performance.
Which strategy for picking an embedding model should they choose?
Answer: A
Explanation:
The task involves improving a Retrieval-Augmented Generation (RAG) application's performance by experimenting with embedding models. The choice of embedding model impacts retrieval accuracy,which is critical for RAG systems. Let's evaluate the options based on Databricks Generative AI Engineer best practices.
* Option A: Pick an embedding model trained on related domain knowledge
* Embedding models trained on domain-specific data (e.g., industry-specific corpora) produce vectors that better capture the semantics of the application's context, improving retrieval relevance. For RAG, this is a key strategy to enhance performance.
* Databricks Reference:"For optimal retrieval in RAG systems, select embedding models aligned with the domain of your data"("Building LLM Applications with Databricks," 2023).
* Option B: Pick the most recent and most performant open LLM released at the time
* LLMs are not embedding models; they generate text, not embeddings for retrieval. While recent LLMs may be performant for generation, this doesn't address the embedding step in RAG. This option misunderstands the component being selected.
* Databricks Reference: Embedding models and LLMs are distinct in RAG workflows:
"Embedding models convert text to vectors, while LLMs generate responses"("Generative AI Cookbook").
* Option C: Pick the embedding model ranked highest on the Massive Text Embedding Benchmark (MTEB) leaderboard hosted by HuggingFace
* The MTEB leaderboard ranks models across general tasks, but high overall performance doesn't guarantee suitability for a specific domain. A top-ranked model might excel in generic contexts but underperform on the engineer's unique data.
* Databricks Reference: General performance is less critical than domain fit:"Benchmark rankings provide a starting point, but domain-specific evaluation is recommended"("Databricks Generative AI Engineer Guide").
* Option D: Pick an embedding model with multilingual support to support potential multilingual user questions
* Multilingual support is useful only if the application explicitly requires it. Without evidence of multilingual needs, this adds complexity without guaranteed performance gains for the current use case.
* Databricks Reference:"Choose features like multilingual support based on application requirements"("Building LLM-Powered Applications").
Conclusion: Option A is the best strategy because it prioritizes domain relevance, directly improving retrieval accuracy in a RAG system-aligning with Databricks' emphasis on tailoring models to specific use cases.
NEW QUESTION # 22
A Generative AI Engineer is tasked with deploying an application that takes advantage of a custom MLflow Pyfunc model to return some interim results.
How should they configure the endpoint to pass the secrets and credentials?
Answer: B
Explanation:
Context: Deploying an application that uses an MLflow Pyfunc model involves managing sensitive information such as secrets and credentials securely.
Explanation of Options:
* Option A: Use spark.conf.set(): While this method can pass configurations within Spark jobs, using it for secrets is not recommended because it may expose them in logs or Spark UI.
* Option B: Pass variables using the Databricks Feature Store API: The Feature Store API is designed for managing features for machine learning, not for handling secrets or credentials.
* Option C: Add credentials using environment variables: This is a common practice for managing credentials in a secure manner, as environment variables can be accessed securely by applications without exposing them in the codebase.
* Option D: Pass the secrets in plain text: This is highly insecure and not recommended, as it exposes sensitive information directly in the code.
Therefore,Option Cis the best method for securely passing secrets and credentials to an application, protecting them from exposure.
NEW QUESTION # 23
A Generative AI Engineer is building a Generative AI system that suggests the best matched employee team member to newly scoped projects. The team member is selected from a very large team. Thematch should be based upon project date availability and how well their employee profile matches the project scope. Both the employee profile and project scope are unstructured text.
How should the Generative Al Engineer architect their system?
Answer: D
Explanation:
* Problem Context: The problem involves matching team members to new projects based on two main factors:
* Availability: Ensure the team members are available during the project dates.
* Profile-Project Match: Use the employee profiles (unstructured text) to find the best match for a project's scope (also unstructured text).
The two main inputs are theemployee profilesandproject scopes, both of which are unstructured. This means traditional rule-based systems (e.g., simple keyword matching) would be inefficient, especially when working with large datasets.
* Explanation of Options: Let's break down the provided options to understand why D is the most optimal answer.
* Option Asuggests embedding project scopes into a vector store and then performing retrieval using team member profiles. While embedding project scopes into a vector store is a valid technique, it skips an important detail: the focus should primarily be on embedding employee profiles because we're matching the profiles to a new project, not the other way around.
* Option Binvolves using a large language model (LLM) to extract keywords from the project scope and perform keyword matching on employee profiles. While LLMs can help with keyword extraction, this approach is too simplistic and doesn't leverage advanced retrieval techniques like vector embeddings, which can handle the nuanced and rich semantics of unstructured data. This approach may miss out on subtle but important similarities.
* Option Csuggests calculating a similarity score between each team member's profile and project scope. While this is a good idea, it doesn't specify how to handle the unstructured nature of data efficiently. Iterating through each member's profile individually could be computationally expensive in large teams. It also lacks the mention of using a vector store or an efficient retrieval mechanism.
* Option Dis the correct approach. Here's why:
* Embedding team profiles into a vector store: Using a vector store allows for efficient similarity searches on unstructured data. Embedding the team member profiles into vectors captures their semantics in a way that is far more flexible than keyword-based matching.
* Using project scope for retrieval: Instead of matching keywords, this approach suggests using vector embeddings and similarity search algorithms (e.g., cosine similarity) to find the team members whose profiles most closely align with the project scope.
* Filtering based on availability: Once the best-matched candidates are retrieved based on profile similarity, filtering them by availability ensures that the system provides a practically useful result.
This method efficiently handles large-scale datasets by leveragingvector embeddingsandsimilarity search techniques, both of which are fundamental tools inGenerative AI engineeringfor handling unstructured text.
* Technical References:
* Vector embeddings: In this approach, the unstructured text (employee profiles and project scopes) is converted into high-dimensional vectors using pretrained models (e.g., BERT, Sentence-BERT, or custom embeddings). These embeddings capture the semantic meaning of the text, making it easier to perform similarity-based retrieval.
* Vector stores: Solutions likeFAISSorMilvusallow storing and retrieving large numbers of vector embeddings quickly. This is critical when working with large teams where querying through individual profiles sequentially would be inefficient.
* LLM Integration: Large language models can assist in generating embeddings for both employee profiles and project scopes. They can also assist in fine-tuning similarity measures, ensuring that the retrieval system captures the nuances of the text data.
* Filtering: After retrieving the most similar profiles based on the project scope, filtering based on availability ensures that only team members who are free for the project are considered.
This system is scalable, efficient, and makes use of the latest techniques inGenerative AI, such as vector embeddings and semantic search.
NEW QUESTION # 24
A Generative AI Engineer is designing a chatbot for a gaming company that aims to engage users on its platform while its users play online video games.
Which metric would help them increase user engagement and retention for their platform?
Answer: C
Explanation:
In the context of designing a chatbot to engage users on a gaming platform,diversity of responses(option B) is a key metric to increase user engagement and retention. Here's why:
* Diverse and Engaging Interactions:A chatbot that provides varied and interesting responses will keep users engaged, especially in an interactive environment like a gaming platform. Gamers typically enjoy dynamic and evolving conversations, anddiversity of responseshelps prevent monotony, encouraging users to interact more frequently with the bot.
* Increasing Retention:By offering different types of responses to similar queries, the chatbot can create a sense of novelty and excitement, which enhances the user's experience and makes them more likely to return to the platform.
* Why Other Options Are Less Effective:
* A (Randomness): Random responses can be confusing or irrelevant, leading to frustration and reducing engagement.
* C (Lack of Relevance): If responses are not relevant to the user's queries, this will degrade the user experience and lead to disengagement.
* D (Repetition of Responses): Repetitive responses can quickly bore users, making the chatbot feel uninteresting and reducing the likelihood of continued interaction.
Thus,diversity of responses(option B) is the most effective way to keep users engaged and retain them on the platform.
NEW QUESTION # 25
A Generative AI Engineer I using the code below to test setting up a vector store: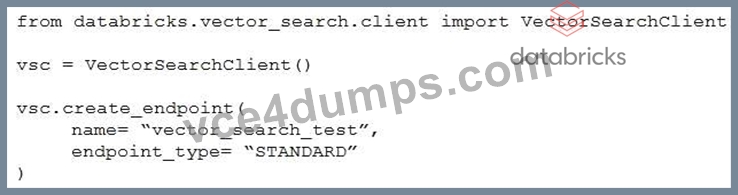
Assuming they intend to use Databricks managed embeddings with the default embedding model, what should be the next logical function call?
Answer: C
Explanation:
Context: The Generative AI Engineer is setting up a vector store using Databricks' VectorSearchClient. This is typically done to enable fast and efficient retrieval of vectorized data for tasks like similarity searches.
Explanation of Options:
* Option A: vsc.get_index(): This function would be used to retrieve an existing index, not create one, so it would not be the logical next step immediately after creating an endpoint.
* Option B: vsc.create_delta_sync_index(): After setting up a vector store endpoint, creating an index is necessary to start populating and organizing the data. The create_delta_sync_index() function specifically creates an index that synchronizes with a Delta table, allowing automatic updates as the data changes. This is likely the most appropriate choice if the engineer plans to use dynamic data that is updated over time.
* Option C: vsc.create_direct_access_index(): This function would create an index that directly accesses the data without synchronization. While also a valid approach, it's less likely to be the next logical step if the default setup (typically accommodating changes) is intended.
* Option D: vsc.similarity_search(): This function would be used to perform searches on an existing index; however, an index needs to be created and populated with data before any search can be conducted.
Given the typical workflow in setting up a vector store, the next step after creating an endpoint is to establish an index, particularly one that synchronizes with ongoing data updates, henceOption B.
NEW QUESTION # 26
......
Do you want to catch up with the trend in the IT industry? Being certified by Databricks Databricks-Generative-AI-Engineer-Associate exam certification means a large possibility of success. While our Databricks-Generative-AI-Engineer-Associate exam targeted training will help you step ahead of others. The valid Databricks-Generative-AI-Engineer-Associate study practice will make your thoughts more clear, and you will have the ability to deal with problem in the practical application. Then, passing the Databricks-Generative-AI-Engineer-Associate Actual Test is an easy and simple thing. If you still have some doubts, please download VCE4Dumps Databricks-Generative-AI-Engineer-Associate free demo for a try. You will be surprised.
Databricks-Generative-AI-Engineer-Associate Exam Engine: https://www.vce4dumps.com/Databricks-Generative-AI-Engineer-Associate-valid-torrent.html
P.S. Free 2025 Databricks Databricks-Generative-AI-Engineer-Associate dumps are available on Google Drive shared by VCE4Dumps: https://drive.google.com/open?id=1t5O376pJ7IPTBazX4_CDV6XhnqxwTbhG
