当社は、すべての受験者が試験に簡単に合格できるようにDP-700最新の練習教材を開発することに専念しており、10年以上の開発の後に大きな成果を上げています。認定資格は非常に価値が高いため、適切なDP-700試験ガイドは、バターを通過するホットナイフのようなDP-700試験に合格するための強力な推進力となります。そして、DP-700試験ガイドの質の高いDP-700学習ガイドは、98%以上の高い合格率によって証明されているため、DP-700試験問題はまさにあなたにとって正しいものです。
| トピック | 出題範囲 |
|---|---|
| トピック 1 |
|
| トピック 2 |
|
| トピック 3 |
|
CertShikenの問題集はIT専門家がMicrosoftのDP-700「Implementing Data Engineering Solutions Using Microsoft Fabric」認証試験について自分の知識と経験を利用して研究したものでございます。CertShikenの問題集は真実試験の問題にとても似ていて、弊社のチームは自分の商品が自信を持っています。CertShikenが提供した商品をご利用してください。もし失敗したら、全額で返金を保証いたします。
質問 # 97
You have a table in a Fabric lakehouse that contains the following data.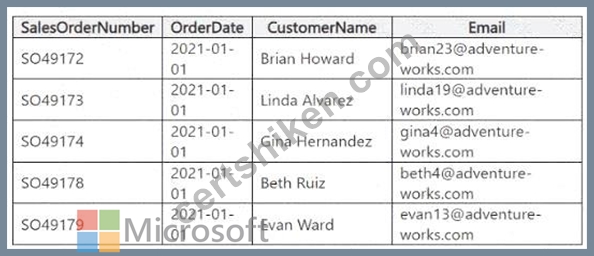
You have a notebook that contains the following code segment.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
正解:
解説:
Explanation:
質問 # 98
You have a Fabric workspace that contains a warehouse named Warehouse1. Data is loaded daily into Warehouse1 by using data pipelines and stored procedures.
You discover that the daily data load takes longer than expected.
You need to monitor Warehouse1 to identify the names of users that are actively running queries.
Which view should you use?
正解:D
解説:
sys.dm_exec_sessions provides real-time information about all active sessions, including the user, session ID, and status of the session. You can filter on session status to see users actively running queries.
質問 # 99
You have an Azure Data Lake Storage Gen2 account named storage1 and an Amazon S3 bucket named storage2.
You have the Delta Parquet files shown in the following table.
You have a Fabric workspace named Workspace1 that has the cache for shortcuts enabled. Workspace1 contains a lakehouse named Lakehouse1. Lakehouse1 has the following shortcuts:
A shortcut to ProductFile aliased as Products
A shortcut to StoreFile aliased as Stores
A shortcut to TripsFile aliased as Trips
The data from which shortcuts will be retrieved from the cache?
正解:C
解説:
When the cache for shortcuts is enabled in Fabric, the data retrieval is governed by the caching behavior, which generally retains data for a specific period after it was last accessed. The data from the shortcuts will be retrieved from the cache if the data is stored in locations that support caching. Here's a breakdown based on the data's location:
Products: The ProductFile is stored in Azure Data Lake Storage Gen2 (storage1). Since Azure Data Lake is a supported storage system in Fabric and the file is relatively small (50 MB), this data is most likely cached and can be retrieved from the cache.
Stores: The StoreFile is stored in Amazon S3 (storage2), and even though it is stored in a different cloud provider, Fabric can cache data from Amazon S3 if caching is enabled. This data (25 MB) is likely cached and retrievable.
Trips: The TripsFile is stored in Amazon S3 (storage2) and is significantly larger (2 GB) compared to the other files. While Fabric can cache data from Amazon S3, the larger size of the file (2 GB) may exceed typical cache sizes or retention windows, causing this file to likely be retrieved directly from the source instead of the cache.
質問 # 100
You are implementing the following data entities in a Fabric environment:
Entity1: Available in a lakehouse and contains data that will be used as a core organization entity Entity2: Available in a semantic model and contains data that meets organizational standards Entity3: Available in a Microsoft Power BI report and contains data that is ready for sharing and reuse Entity4: Available in a Power BI dashboard and contains approved data for executive-level decision making Your company requires that specific governance processes be implemented for the data.
You need to apply endorsement badges to the entities based on each entity's use case.
Which badge should you apply to each entity? To answer, drag the appropriate badges the correct entities. Each badge may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
正解:
解説: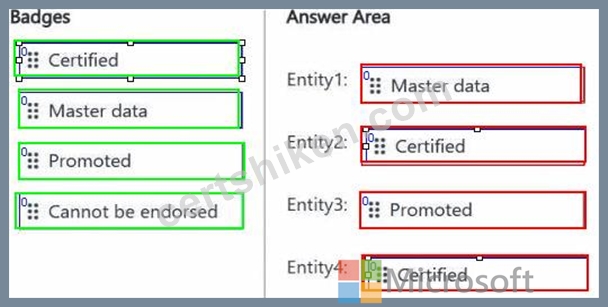
質問 # 101
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a KQL database that contains two tables named Stream and Reference. Stream contains streaming data in the following format.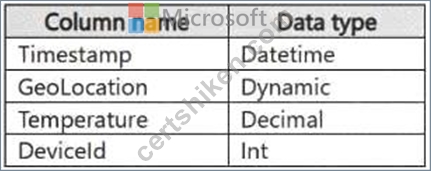
Reference contains reference data in the following format.
Both tables contain millions of rows.
You have the following KQL queryset.
You need to reduce how long it takes to run the KQL queryset.
Solution: You add the make_list() function to the output columns.
Does this meet the goal?
正解:B
解説:
Adding an aggregation like make_list() would require additional processing and memory, which could make the query slower.
質問 # 102
......
CertShikenを通じて最新のMicrosoftのDP-700試験の問題と解答早めにを持てて、弊社の問題集があればきっと君の強い力になります。
DP-700練習問題集: https://www.certshiken.com/DP-700-shiken.html
